
Univeral Approximation Theorem
Published:
This is a starting of Deep learning and machine learning. Mainly talking about Universal approximation theorem. Happy Reading 🙂
First Blog Post
English may be issue in this article but, may be what i am writing is easy to understand so, i will try to share my thoughts here.
Started learning machine learning from 20th Nov and currently studying deep learning different model architectures. At first completed Andrew Ng course on youtube CS 229. Great Course to start with and make foundations concrete. After that learned first principle of computer vision course. Read Understanding deep learning book. This all were done in December. Currently taking deep learning course at IIT Gandhinagar.
Started kaggle in december and submitted 2-3 competitions. These were basic competitions which uses xgboost and linear regression etc. But because of this exercise i learned python libraries, which were easy because of my CS background.
Now i am trying to participate in higher level competitions in kaggle, which includes transformers, rnns, etc. But here i am clueless and not getting any clue how to start with model. How even model works magically with tons of different layers.
I think other students might also have this issue and i think its the biggest concept that any student need to understand to crack into this field.
Starting from the basics
Feed Forward neural network
Everyone knows architecture. The best place to visit this first is 3b1b neural network 3 video series. I think it will cover more than i know. Including things which were covered in understanding deep learning book.
Universal approximation Theorem
Consider shalow neural network architecture. Which has one hidden layer with n number of nodes.
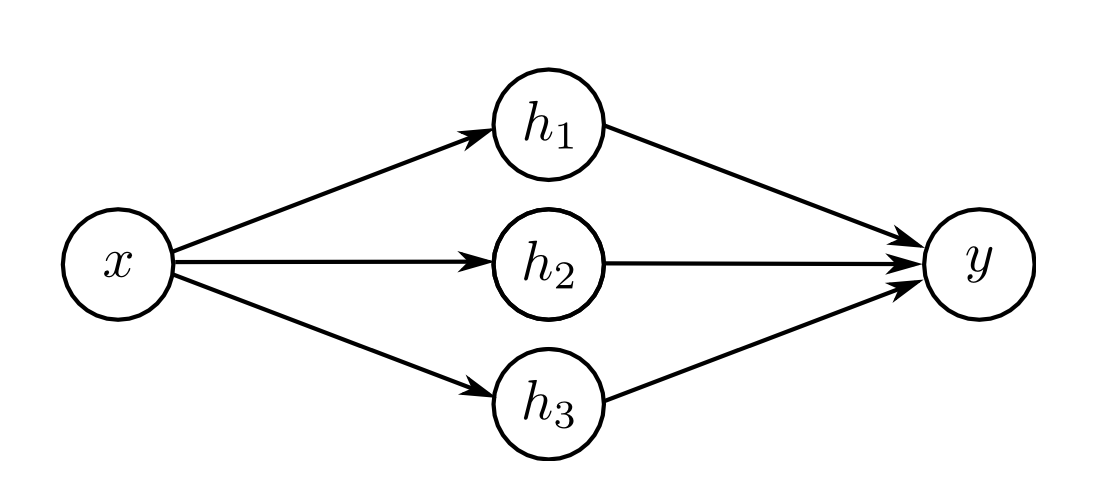
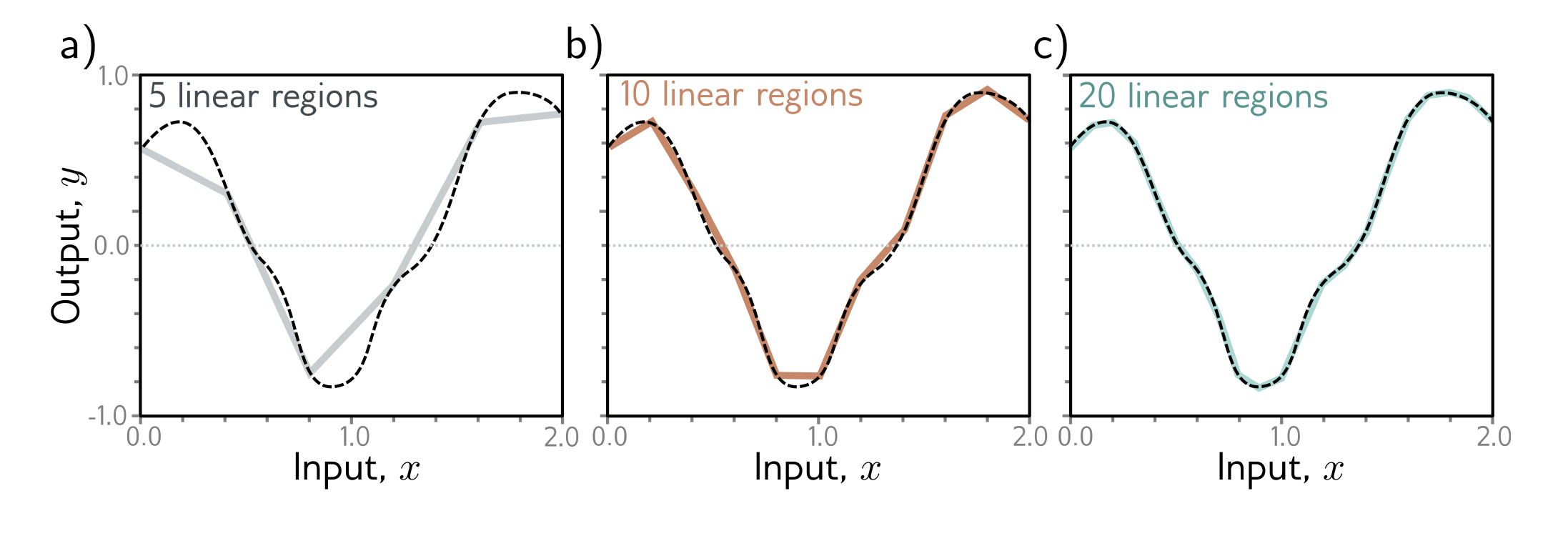
According to theorem with large number of hidden nodes shallow NN can approximate any function. Here activation function used in hidden layer is ReLU then we can easily see that in f:x->y is linear approximation with bumps in slopes of different lines. So, if number of hidden layer node is 3 then we will see 3 lines in graph.
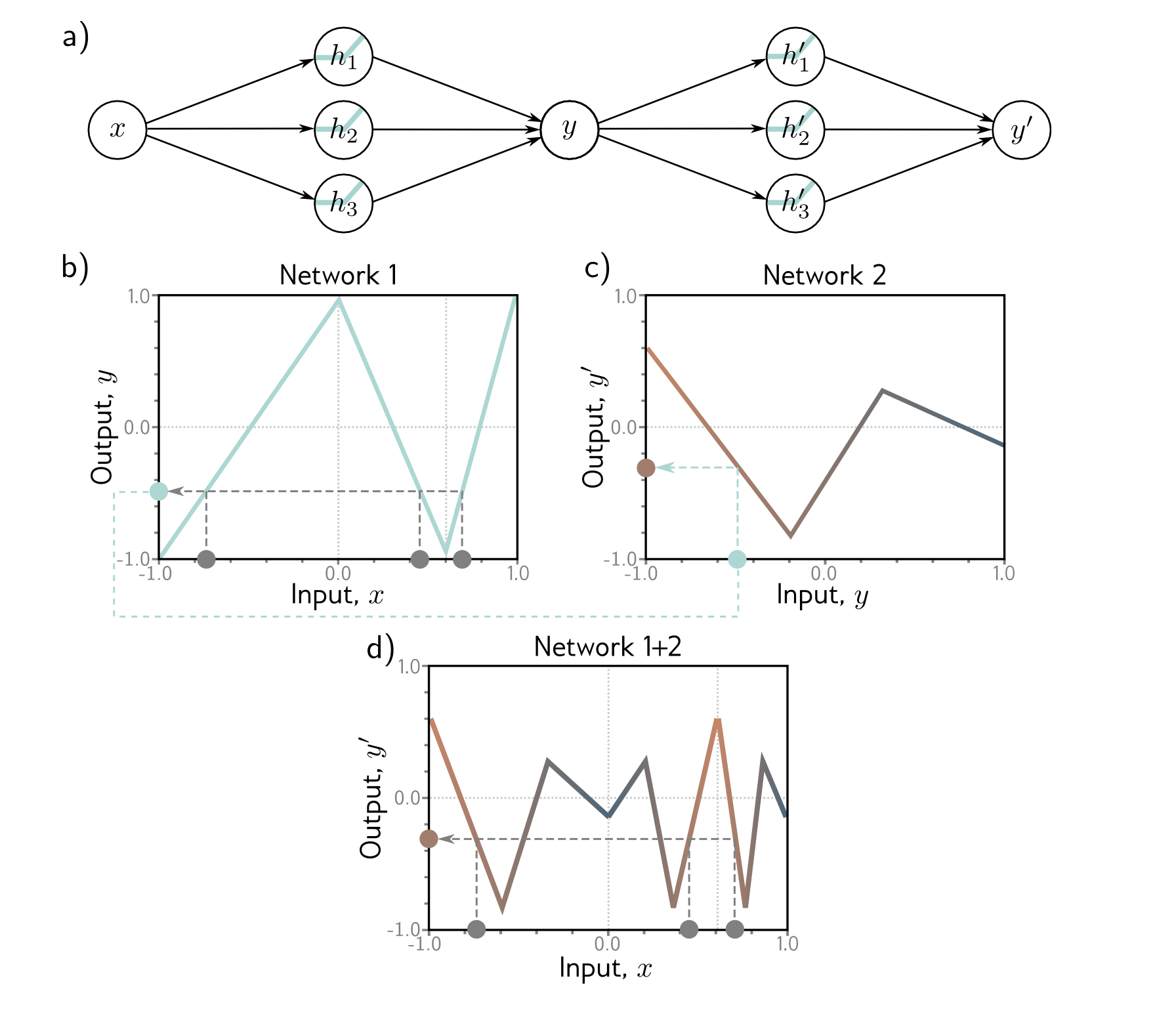
What is the effect when we add more layers. This is easy to see when we add more layer think of 1st hidden layer as input and second layer as 1st hidden layers then you will see that it will segment every lines of first hidden layer to many different lines but this segmented lines are same for all original lines in first hidden layer.
Summary
Understood the basic concept that fully connected neural network can approximate any function with any dimension. Issue here is that when we increase number of hidden layers we get into problem of exploding and vanishing gradients. Also training time will increase drastically. There are many learning is sues and in solution we have different gradient descent algorithms. So, from my understanding tackling any ML problem can be divided in below subparts.
- Do data analysis and choose architecture.
- Choose hyperparameters according to observations of multiple runs.
- Repeat process with different architecture.